
If we previously talked with an agent about something we want to remember, why not ask that agent directly?
Practical implementations of agent-memory systems today often rely on some mix of the following techniques:
- a persisting agent writes “memories” to a file a recalling agent later reads, e.g.
MEMORY.md. - a recalling agent searches over previous session transcripts using tools such as
grep, hybrid search systems, etc.
Duncan Idaho (duncan) explores a third point in the design space. Conceptually, duncan does the following:
DUNCAN_PROMPT="Use only your session context to answer the following question:
Do you have any information about X in your context?"
for session in $prev_sessions; do
cli-agent resume "$session" "$DUNCAN_PROMPT"
doneWhen an agent duncans, it resumes a pool of past agent sessions and asks them to recall information from their immediate context.
This leverages the agents’ native attention mechanism to search over past session contents instead of relying on summaries (which require an agent to speculate ahead of time what information is worth persisting) or search tools (which often do a poor job reconstructing globally coherent context from prior agent sessions).
Here’s what this looks like in practice. I asked my agent to rewrite some code and validate it against a test suite we had previously written. My agent couldn’t find the tests I was referring to and autonomously surveyed seven earlier sessions in the same thread:
Are there any tests for
getCompactionWindowsor theduncanextension? Where are they located? Were any tests written or discussed?”
After reviewing the seven responses, my agent concluded
“tests existed but were deleted after passing. let me recreate one against the refactored code. I’ll pull the test structure from the ancestor sessions.”
and followed up with a second:
“What was the exact content of
/workspace/test-compaction-windows.mjs? Please reproduce the full file content including all imports, helpers, and test cases. I need to recreate it.”
Then the agent restored the test suite (which I, in my wisdom, had intentionally deleted earlier because I didn’t want to think about where to put it lol), verified the cleanup and committed everything.
To make duncan work we need:
- Enough room in the resumed agents’ context windows for processing
duncanqueries. - An algorithm for routing
duncanqueries to target sessions. - The agents, both the source and targets of the
duncan, to faithfully communicate what information is desired and whether or not the target agent’s session context is relevant.
I implemented duncan as an extension to the pi coding agent harness largely because I was playing around with it when the idea occurred to me.
However, because pi extensibility is so good, the implementation proceeded much more quickly than it would have with Claude Code and Codex.
S/o Mario Zechner — it’s a good harness, sir!
First I disabled compaction and replaced it with a variant called /dfork.
/dfork reuses the pi compaction prompt to create a summary and forks a new session instead of continuing in the same one.
This made it easier (at least for me) to reason about routing duncan queries to the appropriate sessions, since the session:context-window mapping is always 1:1 with /dfork instead of stock compaction.
To address the first requirement of the aforementioned “things needed to make duncan work”, I decided (arbitrarily) that a context window buffer of 20% should be more than enough to accommodate all future duncans and added a little warning at 80% saturation that alerts the user it’s time to /dfork.
Next I made another command called /lineage, which allows the user to view and navigate the relationships between sessions in the same working directory (this implements very similar logic to the session picker presented when resuming interactively via pi -r).
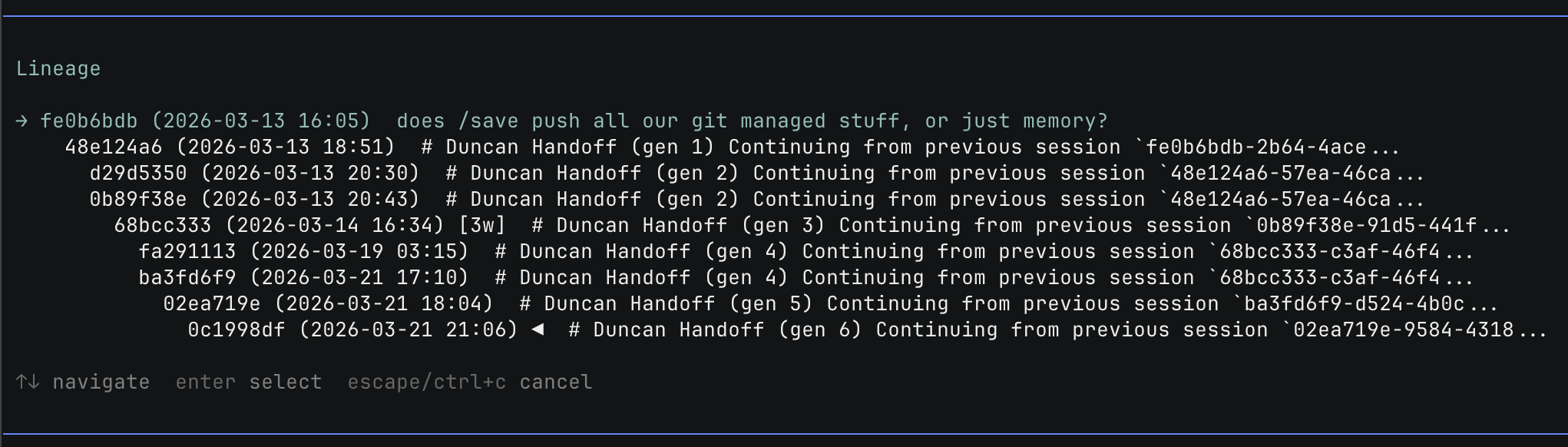
The thinking here was related to the routing question, i.e. item (2) of the duncan requirements.
How should we select which sessions to target?
The simplest solution is to broadcast to all prior agent sessions, which works in cases where the number of sessions is small.
A few localities can be exploited to scope down duncan targets in cases where the number of sessions is large:
- Temporal - more recent sessions are more likely to contain relevant context than older ones.
- Spatial - sessions from the same filesystem path are more likely to contain relevant context than those from other paths.
We can exploit both by walking up through the /lineage (necessarily rooted at the same filesystem path) and batching queries by recency.
When dispatching duncans it’s important to keep target sessions from growing with each successive duncan, otherwise we’d eventually saturate the buffer needed to service future queries.
Also, we don’t want previous question/answer pairs directly impacting the performance of future duncans.
At the time of writing, pi does not natively support “ephemeral” session resume out of the box, so simply spawning pi subprocesses in headless mode for each duncan doesn’t work (without ephemeral support, each duncan would accumulate in the session).
Luckily pi is open source and exposes a ton of useful APIs that the coding agent uses for its own harness, which we repurpose for duncan dispatch.
Let’s walk through some technical details of how sessions work in pi2 so we can understand how they make their way into an LLM’s context window.
Each session is a jsonl file that lives in a config directory.
This session file is an append-only structure of entrys, with backpointers from the last leaf entry chained all the way up to the root.
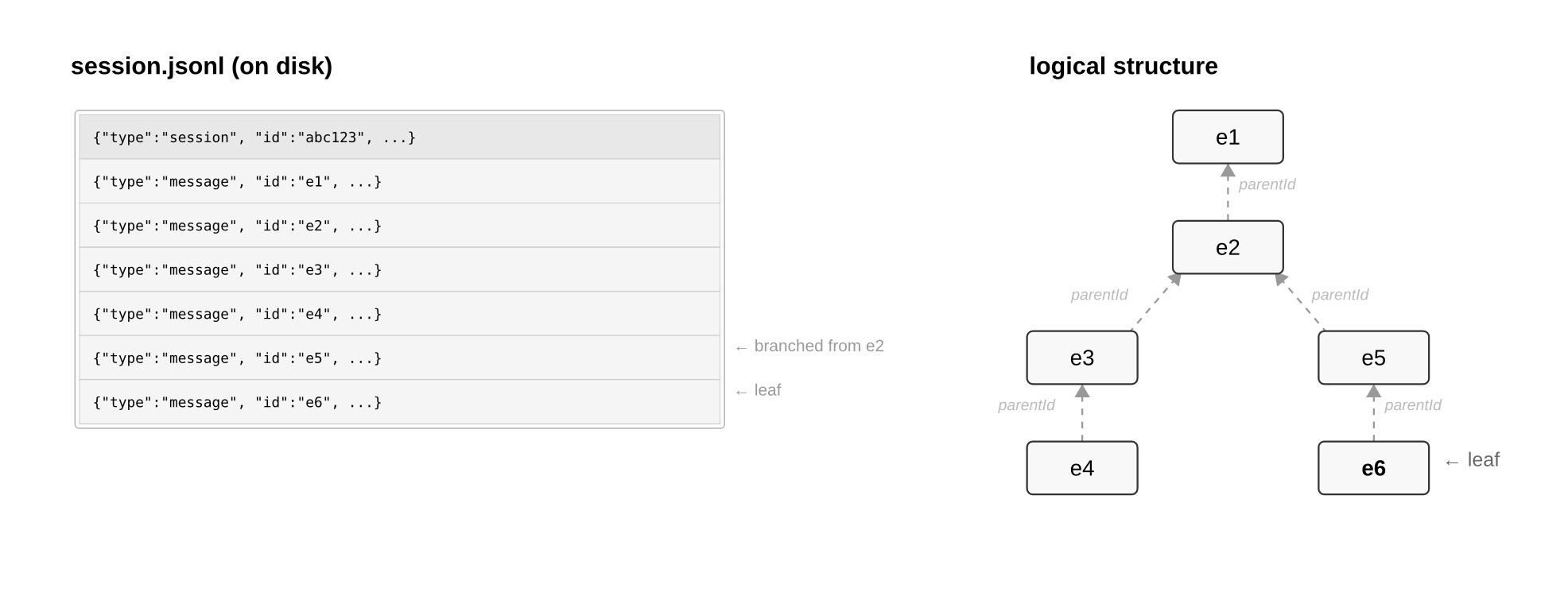
When converting session contents to LLM API calls during resume, pi:
- walks the session
parentIdchain from leaf to root viabuildSessionContext()and returns anAgentMessage[]encoding the contents of the session. - passes the
AgentMessage[]toconvertToLlm()and returns aMessage[], an intermediate representation of the session contents. - passes the
Message[]tostreamSimple(), which serializes theMessage[]to a specific provider’s API and streams a response back to the TUI.
For each target session, duncan executes exactly3 the same steps as the above.
This symmetry gives us a lighter-weight alternative to spawning pi subprocesses while also granting us deeper control over the response, which leads us to the third duncan requirement.
We need agents to have a good understanding of what they do and don’t know.
We get this for free with the latest generation of models, especially when it comes to questions of the form “Do you have any information about X in your context?”
The prompting itself is trivial — you just have to tell the agent to rely only on the session context and answer in the negative if it lacks relevant context (the actual prompts are here).
However, recall the earlier point about not allowing answers generated in service of duncan to pollute the session structure.
That was not to say the responses aren’t worth persisting!
To make the responses amenable to future analysis (perhaps a duncan router can be learned or otherwise constructed from the response corpus), we expose a single duncan_response tool to the target sessions (denying all other tools) and force the response into a structured output with the following schema:
{ hasContext: boolean, answer: string }where hasContext is a simple indicator of whether the session had relevant context and answer is the affirmative response or an explanation of what was lacking (the latter tends to be uninteresting).
This allows us to persist these answers in our own duncan.jsonl, and to manipulate the response programmatically for display (e.g. filtering out tons of “no context” responses from a large fan-out).
The final implementation wrinkle relates back to technical session details — making duncan compaction-compatible and removing the dependency on /dfork.
compaction is simply another entry in the session ledger, appended the same way every other entry is.
compaction signals the session-to-LLM-context builder to only include messages from the entry specified by firstKeptEntryId down.
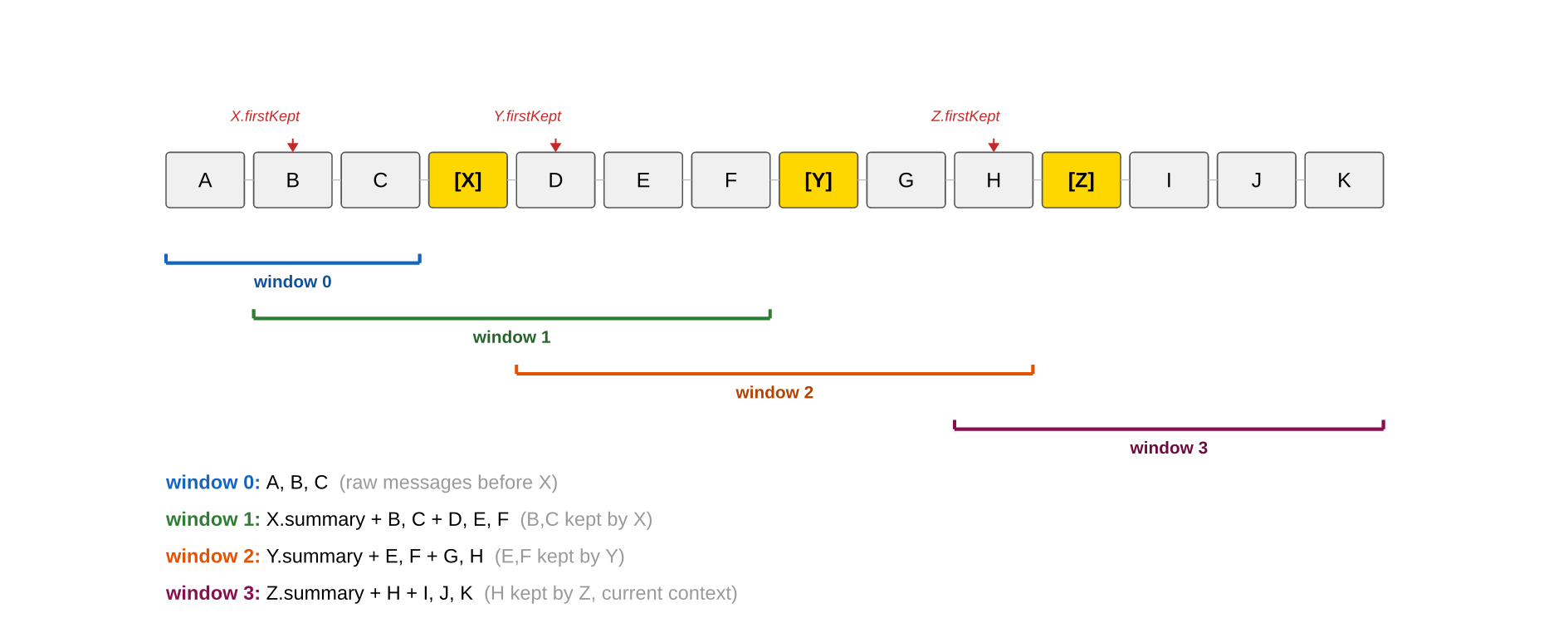
For example, given the following session:
entry A (old)
entry B (old)
entry C (old)
entry D ← firstKeptEntryId
entry E
compaction entry (summary of A+B+C)
entry F (new)
entry G (new)the session-to-LLM-context builder will populate the context window with the following:
compactionsummary (covering A, B, C)- D, E (kept verbatim — between
firstKeptEntryIdand the compaction) - F, G (everything after the compaction)
duncan maintains parity with pis compaction handling when populating the context window with session contents via getCompactionWindows().
When parsing a session file with multiple compactions X, Y, and Z, duncan will operate over all the compacted ranges, restoring each “window” to its state just prior to the subsequent compaction to service the query (excluding itself, in the case where duncan is querying prior ranges in the active session):
There you have it! We covered the main technical ideas behind duncan. The extension has more routing strategies than discussed in this post for accommodating various recall patterns (ancestors, descendants, project-wide, specific sessions, global), but they all operate on the principles described above.
With that said, duncan is obviously not free.
It adds latency and can fan out expensively if routed poorly.
It doesn’t replace summaries or search, but complements them by recovering context never explicitly persisted or awkward to recover with more basic agentic search techniques.
Alas, dear reader, you’ve managed to slog your way through to the end of my technical ramblings (or just scrolled here), and for this you shall be rewarded! Here be SPOILERS that discuss deep Dune lore. Read no further if you have not completed the first six books of the Dune series but want to experience it unsullied.
To cut a long story short, Duncan Idaho is, due to the capricious will of Leto II the God Emperor, the Bene Gesserit, and the Tleilaxu, resurrected as a ghola (a clone grown from the dead cells of the original Duncan Idaho) countless times over the millennia.
Toward the end of his character arc, the final Duncan awakens to his own variation of “genetic memory”, gaining access to the memories and experiences of all his past incarnations.
In a similar way, when an agent duncans, the agent brings back its previous incarnations to have a chat and probe their memories.
The Duncans never forget!

1. Yes, this is an actual quote from God Emperor of Dune. back
2. Interestingly, pi, Claude Code, and Codex all implement sessions in roughly the same manner. While this walkthrough discusses pi session handling internals, the concepts are generally applicable to Claude Code and Codex as well. back
3. duncan calls completeSimple(), which is just a non-streaming wrapper around streamSimple(). back